Indekser
Hvorfor bruke indekser?
- For å gjøre queries raskere
- Student (pnr, studnr, navn, adresse, epost)
- SELECT navn, adresse FROM Student WHERE studnr=123456;
- Film (id, fnavn, år, selskap, nasjonalitet, score)
- SELECT fnavn, år FROM Film WHERE score > 7.0;
- For å tvinge gjennom UNIQUE og PRIMARY KEY-restriksjoner
- Ha indeks på det som er unikt
- Student (pnr, studnr, navn, adresse, epost)
Begreper innen indeksering
- Indeksfelt: Felt / attributt av posten som indeksen bruker
- Primærindeks: Indeks på primærnøkkelen
- Clustered indeks: Indeks på en tabell hvor postene er fysisk lagret sammen med (i) indeksen
- I MySQL får du clustered indeks automatisk
- Sekundærindeks: Ekstra indeks på et annet felt hvor det også finnes en primærindeks.
- Sekundærindeksen kan være brukt for å tvinge gjennom UNIQUE, dvs. en unik verdi for hver post i tabellen
- Student (pnr, studnr, navn, adresse, epost)
Lagrings- og indekseringsmuligheter (1)
- Systemspesifikt, se dokumentasjon av «ditt» system
- Clustered B+-tree / clustered index
- B+-tre på primærnøkkel
- Løvnivå av treet lagrer selve posten
- MySQL: InnoDB
- SQL Server: Clustered index når primærnøkkel er definert
- Heapfil og B+-tre
- Tabell lagret i heapfil
- B+-tre på primærnøkkel. Postene blir da (key, RecordID)
- Evt. annen indeks på et annet felt
- MySQL: MyISAM
- SQL Server: Heap + unclustered index
Lagrings- og indekseringsmuligheter (2)
- Heapfil
- Postene lagres forløpende uten noen annen organisering
- SQL Server: Hvis primærnøkkel ikke er definert
- Clustered hash index
- Hashindeks på primærnøkkel
- Posten lagret i indeksen
- Oracle: Hash cluster
- LSM-trees (log-structured merge trees)
- Google: Big Table
- Moderne lagrings- og indekseringsmetode for Big Data
- ..som er stadig voksende.
- «Cacher» de nyeste innsatte/oppdaterte postene.
- Høy skriveytelse, lav «write amplification», bedre komprimering
- Eldre poster flyttes over i «langtidslager» (flere nivåer)
- Sqlite3, NoSQL, RocksDB, MySQL/myRocks, Apache Hbase
Lagrings- og indekseringsmuligheter (3)
- Column stores
- Tradisjonelt lagres tabellens rader i SQL-databaser
- Analyseapplikasjoner / datavarehus vil oppleve bedre ytelse med kolonnebasert lagring
- Leser mindre data ved queries og kan bruke komprimering
- Kan komprimere på flere måter
- SELECT MAX(score) FROM Film;
- SQL Server: Columnstore index + delta store for å samle nok oppdateringer til å flette sammen med kolonnen.
- Apache Kudu (Hadoop platform), C-store/VoltDB
- AI-genererte indekser (f.eks. Recursive Model Indexes)
- Indekser laget basert på maskinlæring
- Svært effektive på read-only data, men sliter med oppdateringer
- Genererer indekser på eksisterende data, kan være problematisk ved innsetting
B+-trær
- Den mest brukte indeksen
- Høydebalansert tre med blokker som noder
- Alle «brukerposter» er på løvnivå («nederst»)
- Typisk høyde: 2, 3 eller 4.
- Ikke som i algdat! Høyden er antall nivåer.
- Minimum 50 % fyllgrad i blokker
- Gjennomsnittlig 67 % fyllgrad i blokker
- Postene er sortert på nøkkelen, og treet støtter da
- Likhetssøk (direktesøk)
- Verdiområdesøk
- Sekvensielle, sorterte skan
- Gode på det meste, også for dynamiske datamengder
- Ikke så gode på innsetting av store mengder
B+-tre, eksempel
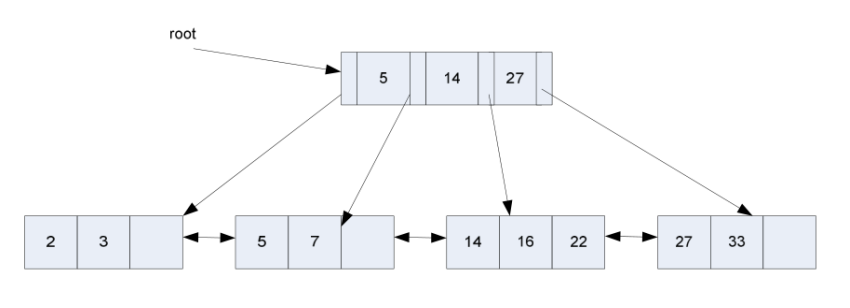
B+-trær i praksis
- Typisk fanout: 133
- Typisk fyllgrad: 67 %
- Typisk kapasistet (non-clustered B+-tree)
- Høyde 3 : 1333 = 2 352 637 poster
- Høyde 4 : 1334 = 312 900 700 poster
- Clustered B+-tre
- Høyde 4: 133 _ 133 _ 133 * 20 = 47 millioner poster
- I praksis er de øverste nivåene alltid i buffer (RAM)
- Level 3 1 blokk 8 KB
- Level 2 133 blokker 1 MB
- Level 1 17 689 blokker 133 MB
- Level 0 2,3 mill blokker 18 GB
Poster i B+-trær
- Tabell: Student (pnr, studnr, navn, adresse, epost)
- Clustered B+-tree
- Løvnivå (level=0):
- Hver post på løvnivå vil se slik (‘010195 12345’, 123456, ’Hans Hansen’, ’Revekroken 1’, ’hans@stud.ntnu.no’)
- Hver blokk på løvnivå kan inneholde ca. 150 poster (avhengig av blokkstørrelse)
- Level > 0 (indeksnivå):
- (‘020194 23456’, BlockId)
- Hver blokk kan inneholde ca. 600 poster (antar indekspost er ¼ av en vanlig post)
Quiz 1
- Hvorfor brukes B+-trær?
- De finnes overalt ✅
- Superraske til å søke på mobilnr
- Gode på det meste ✅
- Passer veldig bra til moderne cachearkitektur
- Hvordan lagre: Det søkes etter primærnøkkel og hele posten trengs?
- Heapfil
- Hashfil
- Clustered B+-tre ✅
- Clustered Hashfil ✅
Quiz 2
- Et B+-tre har kun ett nivå, hvor mangel blokker i treet?
- 1 ✅
- 10
- 100
- 1000
- Det søkes etter nøkkel 15. Hvor mange blokker aksesseres?
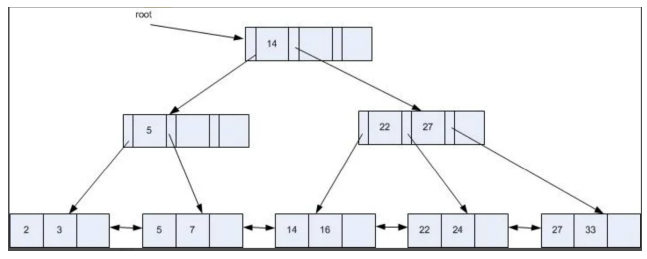
Blokksplitting i B+-tre
- Splitting vanligvis ved midterste post
- Størrelsesmessig midterste post ved variabel lengde poster
- Maks poststørrelse kan være ½ blokk, men spesialløsninger for virkelig lange poster (BLOBs)
- Indeksposter (level > 0) er små: nøkkel + BlockId
- Løvnodeposter kan være større. Hvorfor?
Indekser på sammensatte nøkler
- Employee (ssn, dno, age, street, zip, salary, skill)
- SELECT * FROM Employee WHERE dno=4 and age>50;
- Hvilke indekser kan hjelpe her?
- Indeks på dno: finn alle poster med dno=4 og sjekk om age > 50
- Indeks på age: scan indeksen fra 50 og finn alle poster med dno=4.
- Sammensatt indeks på
- (age, dno)
- (dno, age)
- Bruk den som er mest selektiv først, altså den som gir færrest poster i resultatet
- Indekspostene har leksikalsk sortering