Queryutføring
Algoritmer for queryprosessering og optimalisering, kap. 18 + notat
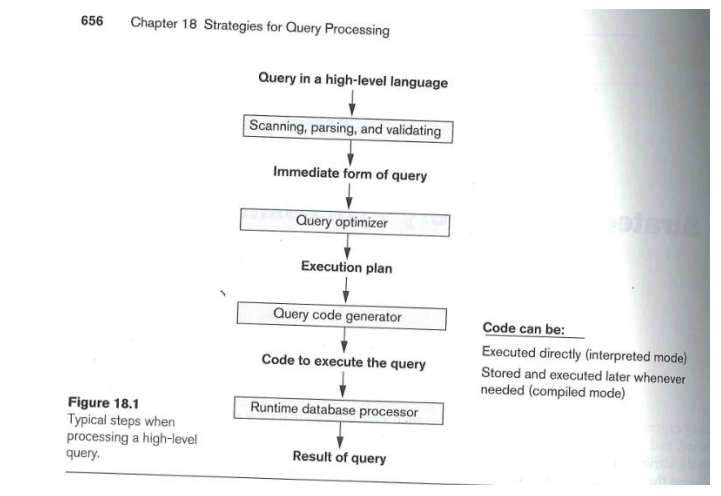
Fra Query til resultat (18.1)
Teknikker for å utføre relasjonsalgebraoperasjoner (18.3)
- Indeksering: Bruk WHERE-uttrykk til å trekke ut små mengder poster (seleksjon, join)
- Iterasjon: Ofte er det raskest å scanne hele tabeller
- Partisjonering: Sortering og hashing av input gir operasjoner på mindre datamengder
- NTNU er kjent som pionerer på hashbaserte metoder (partisjonering). Kjell Bratbergsengen, VLDB 1984.
Statistikk om data
- For hver tabell
- antall rader
- antall blokker
- For hver indeks
- antall nøkkelverdier
- antall blokker
- Histogrammer
- For hvert B+-tre
- Trehøyde
- LowKey
- HighKey
- antall blokker
Aksessvei (18.3)
- Access path / search method (E & N)
- Optimalisatoren velger den billigste aksessveien
- Måles i antall blokker som aksesseres (+ CPU-bruk)
-
- Filscan (tabellscan)
-
- Indeks – Indeksscan – Rangescan – Indeks lookup
Optimalisatortre
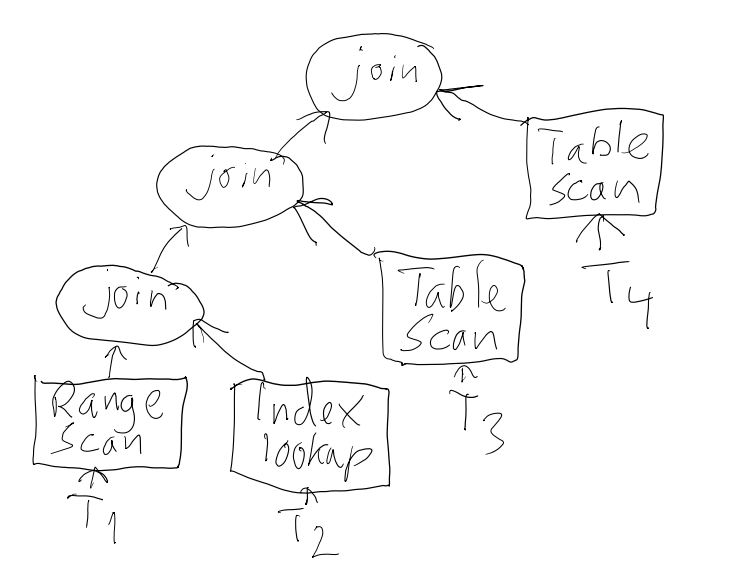
Bruk explain i MySQL
- MySQL leser tabellene i den gitte rekkefølgen
- ALL: Full table scan

Flettesortering (18.2)
- Merge-sort: Sortering av store datamengder
- 2 faser
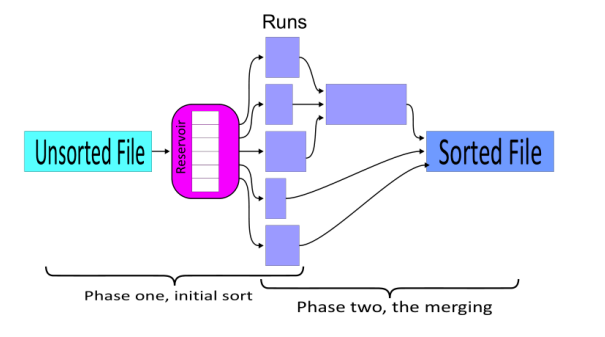
Flettesortering (2)
- Partisjonering
– Sorterer deler (partisjoner) som får plass i RAM
- Antall deler (partisjoner): nR
- Antall blokker av data: b
- Tilgjengelige buffer: nB
- Fletting – Flett sammen sorterte delfiler i et antall pass – Flettegrad dM – antall delfiler som kan flettes i hvert pass – Flettepass – antall pass som filene må flettes i
- Regner ut total I/O – antall blokker som leses/skrives
Metoder for enkle seleksjoner (18.3.1)
- Lineært filscan (S1)
- Bruk B+-tre eller hashindeks (clustered index) (S5)
- Bruk sekundærindeks (unclustered index) (S6)
Metoder for utføring av join (18.4.1)
- J1: Nested-loop join
– For hver blokk i den ene tabellen
- Scan hele den andre tabellen og se etter match
- J2: Single-loop join (index nested loop)
- Loop gjennom den ene tabellen og bruk en indeks for å slå opp i den andre
- J3: Sort-merge join:
- Hvis begge tabellene er sorterte på joinattributtene, kan vi bare flette de
- Hvis ikke, kan de sorteres først, og så flettes
- J4: Partition-hash join
- Partisjoner tabellene ved hashing på joinattributtene
- Får mange små partisjoner som kan joines parvis i RA